Neste artigo, o autor tenta responder à pergunta: existe uma relação entre a relação entre ações ecrescimento (estoque para fluxo ou S2F) e custobitcoin. Ele verifica o modelo logarítmico do Plano B proposto para significância estatística, com base no método dos mínimos quadrados, para a invariabilidade de cada uma de suas variáveis ao longo do tempo, e para possíveis dependências falsas. Um modelo de correção de erro vetorial (VECM) foi criado e testado com base no modelo stock-to-gain original. Embora alguns desses modelos sejam superiores ao original em termos do critério de informação de Akaike, todos eles falham em refutar a hipótese de que o estoque para ganho é um indicador importante e falso do preço do bitcoin.
1. Introdução
O método científico é difícil para a maioria das pessoas.É contra-intuitivo e, portanto, pode levar a conclusões que não refletem as opiniões dos autores. Para compreender este método é necessário compreender e aceitar a sua ideia fundamental:cometer erros normalmente... Isso deve ser ensinado na escola.Se tivermos medo de cometer um erro, nunca seremos capazes de oferecer nada de novo. A história da descoberta científica está cheia de acidentes felizes. Descobertas e descobertas acidentais podem ser tão (ou até mais) importantes do que aquilo em que estavam trabalhando na época. As ideias podem ser falhas ou inconclusivas, mas o que é descoberto no processo de testá-las cria a base para os seguidores.
De acordo com o grande filósofo da ciência CharlesPopper, testar uma hipótese para ver se ela está errada é a única maneira confiável de adicionar peso ao argumento de que ela é verdadeira [1]. Se testes rigorosos e repetidos não puderem provar que uma hipótese está errada, então, com cada um desses testes, a probabilidade de que ela seja verdadeira aumenta. Este conceito é chamado de falsificabilidade (ou falsificabilidade potencial) de uma teoria. Neste artigo, tentarei manipular o modelo Stock-to-Flow de descoberta de preços do Bitcoin descrito no artigo do Plano B “Modelando o preço do Bitcoin com base na escassez”. [2].
Definição do problema
Para falsificar uma hipótese, você deve primeiro estabelecer em que consiste:
Hipótese nula (H0): o valor do Bitcoin é uma função de sua relação estoque / fluxo
Hipótese alternativa (H1): o valor do Bitcoin não é uma função de sua relação estoque / fluxo
O Plano B em seu artigo [2] decidiu verificar H0,correlacionar regressão de mínimos quadrados ordinários (OLS) no logaritmo natural da capitalização de mercado do Bitcoin e o logaritmo natural da relação estoque / fluxo. O autor não forneceu nenhum diagnóstico concomitante ou qualquer razão definitiva para a transformação logarítmica de ambas as variáveis, exceto a ideia de que o modelo log-log pode ser expresso como uma lei de potência. Por ser não estacionário, este modelo não leva em consideração a possibilidade de estabelecer falsas dependências.
Método
No artigo de hoje, daremos uma olhada neste modelo,iremos diagnosticar a regressão normal e determinar se a transformação do logaritmo foi necessária ou aconselhável (ou ambos), e também investigaremos possíveis fatores de confusão (fatores de confusão), interações e sensibilidade.
Outro problema que estamos investigando éo problema da não estacionariedade. A estacionariedade (invariabilidade ao longo do tempo) é uma condição necessária para a maioria dos modelos estatísticos. Isso se refere à ideia de que, se não houver tendência relativa ao tempo na média (ou variância), ela estará ausente a qualquer momento.
Além da análise de estacionariedade, também estamos explorando a possibilidade de cointegração.
Legend
Tradicionalmente, o valor calculado de um parâmetro estatístico é indicado por um «cap» acima do símbolo. Aqui usaremos [ ], ou seja, valor calculadoβ= [β].Representaremos a matriz 4×4 como [r1c1, r1c2 r2c1, r2c2], etc. Para denotar elementos indexados, usaremos o símbolo @ — por exemplo, para a 10ª posição em um vetor X, normalmente usaríamos X com o subscrito 10. Em vez disso, escreveremos X@10.
Mínimos quadrados ordinários (OLS)
A regressão regular de mínimos quadrados é um método para encontrar uma relação linear entre duas ou mais variáveis.
Primeiro, vamos definir um modelo linear como alguma função X, que é igual a Y com algum erro.
Y = βX + ε
onde Y é a variável dependente, X é a variável independente,εé a magnitude do erro, eβ– multiplicadorX. O trabalho do OLS é gerar o valorβde modo a minimizarε.
A fim de obter um valor calculado confiável [β], é necessário observar algumas condições básicas:
- A presença de uma relação linear entre variáveis dependentes e independentes
- Homocedasticidade (ou seja, variação constante) de erros
- A média da distribuição do erro geralmente é zero.
- Falta de autocorrelação de erros (ou seja, eles não se correlacionam com a sequência de erros cometidos com uma mudança de horário)
Linearidade
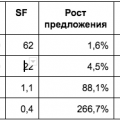
Vamos começar examinando o índice não disperso de capitalização de mercado e o índice S2F (dados da fonte [4]).
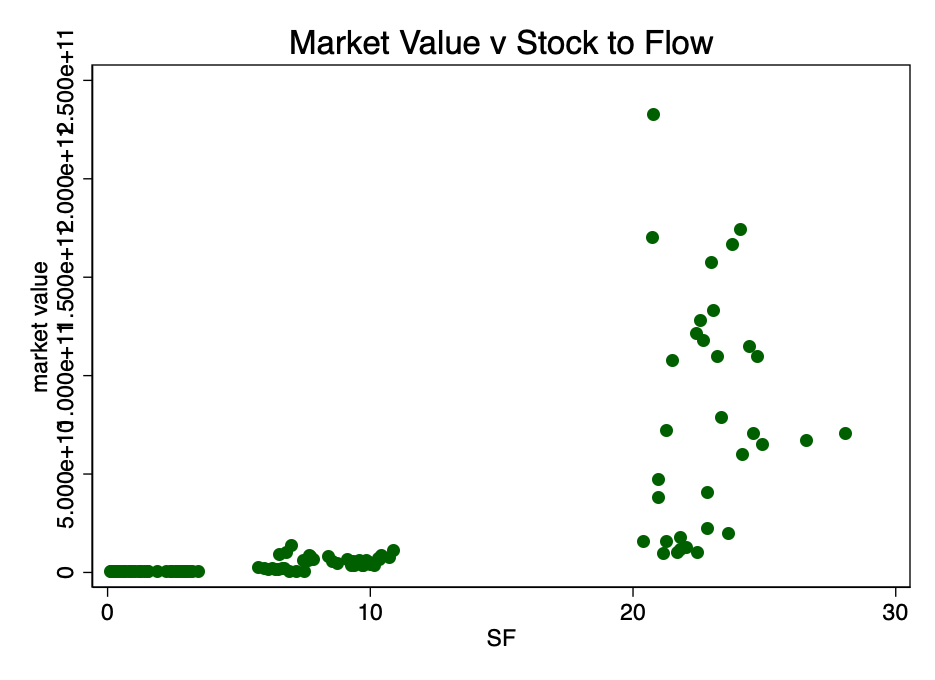
Figura: 1 - O rácio entre a capitalização do mercado e o rácio Stock-to-Flow. Os dados são escassos para estabelecer uma relação.
A Figura 1 mostra claramente uma razão suficiente paratomando o logaritmo do valor de mercado: o intervalo de valores é muito grande. Pegando o log do valor de mercado (mas não S2F) e re-plotando o gráfico, obtemos um padrão familiar (Figura 2).
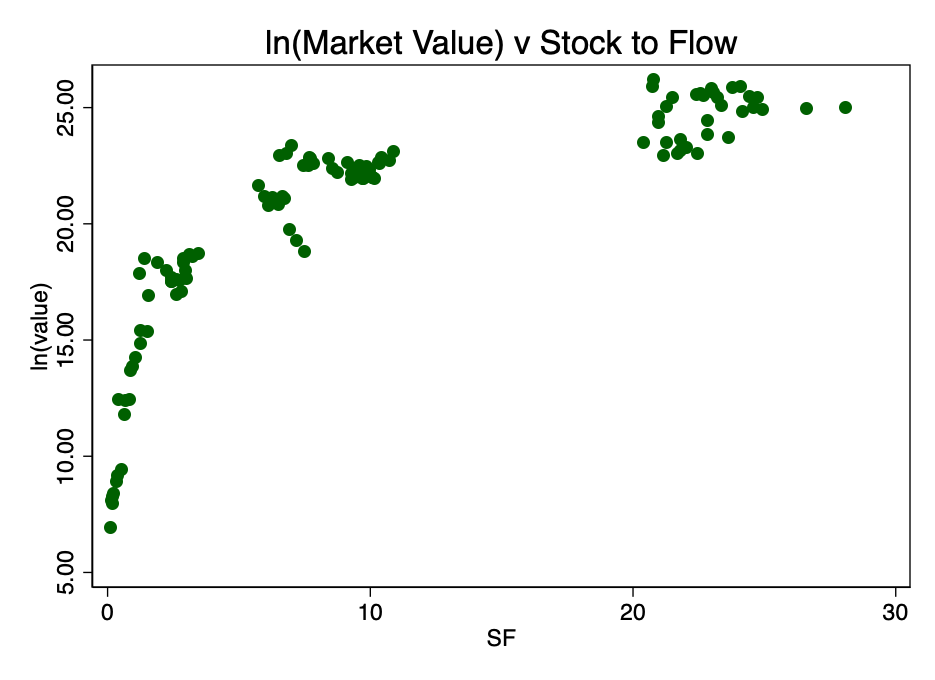
Figura: 2 - a relação entre o logaritmo da capitalização de mercado e o coeficiente S2F Um padrão logarítmico distinto emerge.
Pegando o logaritmo do coeficiente S2F e construindo um diagrama com ele, obtemos um padrão linear óbvio identificado pelo autor da fonte [2] (Plano B) na Figura 3.
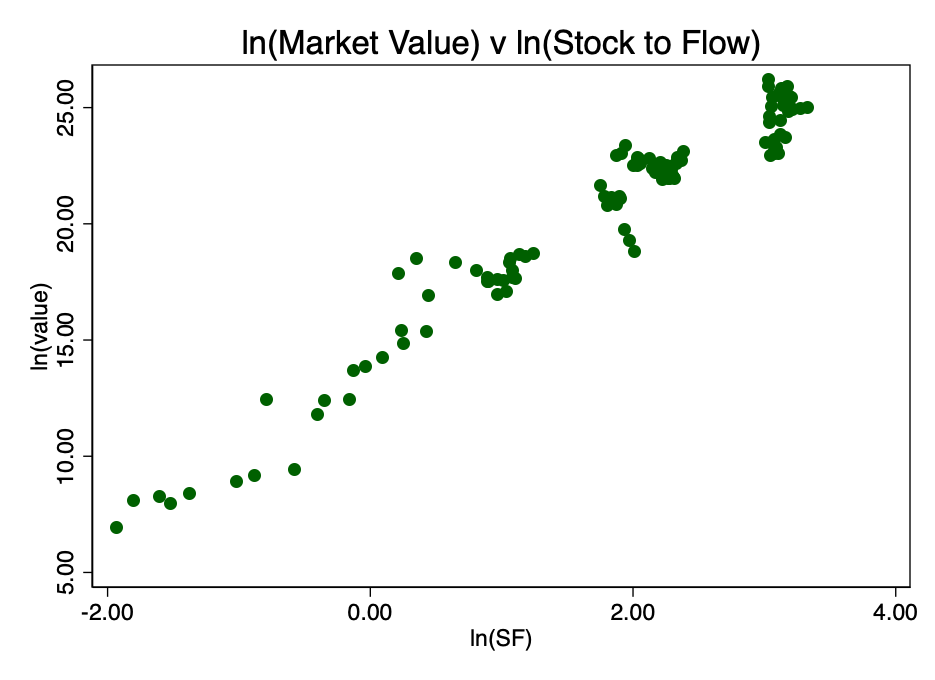
Figura: 3 - razão dos logaritmos da capitalização de mercado e coeficiente S2F. Surge uma relação linear óbvia.
Isso confirma a escolha correta do logaritmo duplo como a única opção que resulta em um relacionamento linear bem visível.
Uma opção de conversão alternativa era encontrar a raiz quadrada de ambos os parâmetros. O padrão resultante é mostrado na Figura 4.
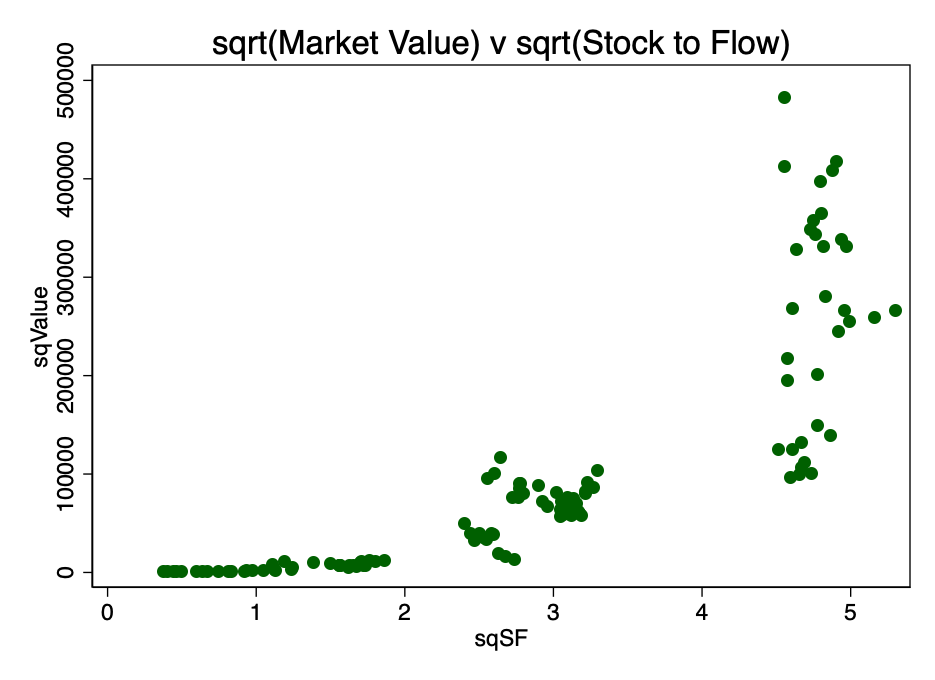
Figura: 4 é o resultado da conversão calculando a raiz quadrada do valor de mercado e o fator S2F.
Obviamente, o logaritmo duplo é a transformação mais apropriada para satisfazer a primeira condição, a linearidade.
Assim, a análise preliminar não refuta H0.
Os resultados da regressão logarítmica dupla são mostrados na Figura 5 abaixo, onde [β] =[3.4, 3.7](intervalo de confiança de 95%).
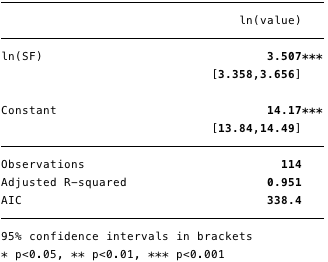
Figura: 5 - resultados para regressão logarítmica dupla.
Usando esse modelo, agora podemos determinar os resíduos [ε] e valores calculados [Y] e também verifique a conformidade com outras condições.
Homoskedasticity
Se a condição de dispersão constante emQuanto à magnitude do erro (isto é, homocedasticidade), o erro para cada valor do custo previsto flutua aleatoriamente em torno de zero. Portanto, o gráfico da relação entre o valor residual e o valor estimado (Fig. 6) é uma forma simples, mas eficaz de verificar graficamente o cumprimento desta condição. Há algum padrão em vez de dispersão aleatória na Figura 6, indicando que a variação na magnitude do erro é inconsistente (ou seja, heterocedasticidade).
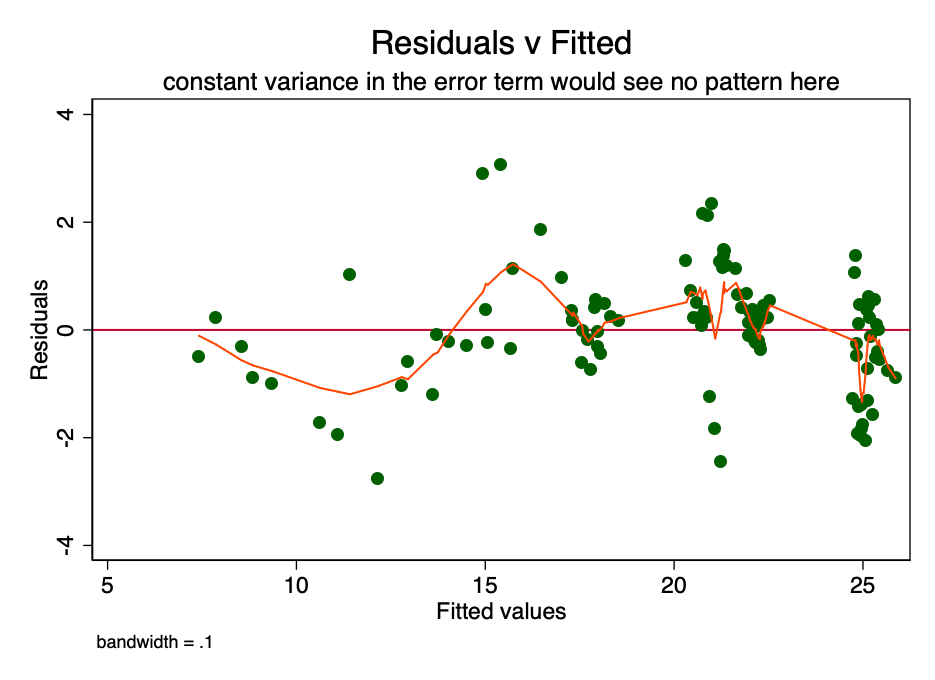
Figura: 6 é um gráfico da razão entre o valor residual e o estimado. Com uma variância constante do erro, o padrão não seria observado. A presença de um padrão indica um possível problema.
A consequência dessa heterocedasticidade é uma maior dispersão e, consequentemente, uma menor precisão dos valores calculados dos coeficientes [β]Além disso, leva a maior do que deveria ser a significância dos p-valores, uma vez que o método OLS não revela aumento da variância. Portanto, para calcular os valores t e F, usamos um valor subestimado da variância, levando a uma significância mais alta. Também afeta o intervalo de confiança de 95% para [β], que também é uma função de variância (por meio do erro padrão).
Neste ponto, você pode continuar com segurançaregressão, tendo consciência da existência destes problemas. Existem maneiras de lidar com eles - por exemplo, obtendo amostras de bootstrap ou estimativa robusta de variância.

Figura: 7 - O efeito da heterocedasticidade é mostrado em estimativa robusta.
Como pode ser visto na Figura 7, apesar do pequenoum aumento na variância (ver intervalo de confiança estendido), em geral, a heterocedasticidade presente não tem realmente um efeito prejudicial.
Neste estágio, não podemos refutar H0 devido à heterocedasticidade.
Distribuição de erro normal
Satisfação da condição em que o erro ema norma é distribuída com valor médio zero, não tão importante quanto satisfazer as condições de linearidade ou homocedasticidade. Se os resíduos não forem normalmente distribuídos, mas não distorcidos, os intervalos de confiança serão excessivamente otimistas. Se os resíduos estiverem distorcidos, o resultado final também pode ser distorcido. No entanto, como pode ser visto nas Figuras 8 e 9, os resíduos estão dentro da faixa normal. A média parece ser cerca de zero e, embora um teste formal provavelmente refutasse a hipótese de distribuição normal, os resíduos se ajustam à curva de sino apenas o suficiente para que os intervalos de confiança não sejam afetados.
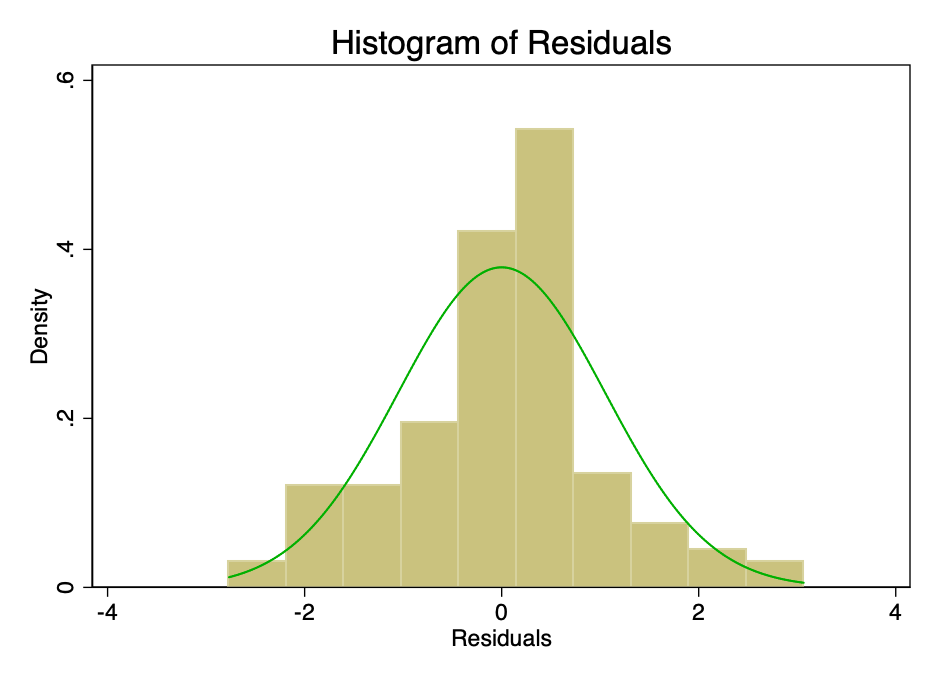
Figura: 8 - histograma do erro com curva de distribuição normal sobreposta (verde).
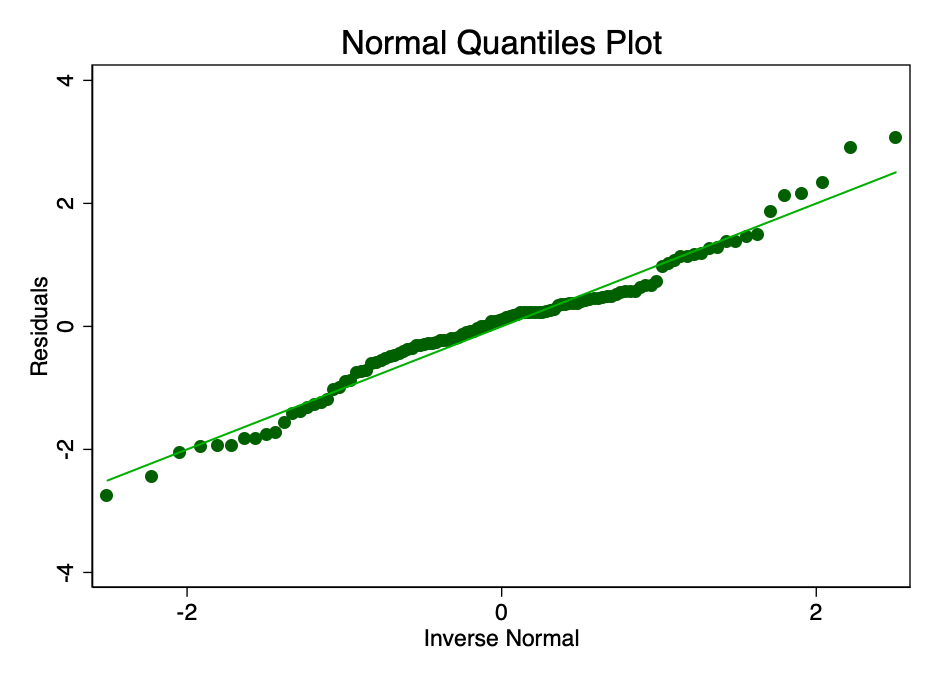
Fig. 9 é um gráfico com quantis normais do valor do erro. Quanto mais próximos os pontos da linha, melhor o ajuste normal.
Força de impacto (alavancagem)
Alavancagem aqui é um conceito segundo o qualnem todos os pontos de dados na regressão contribuem igualmente para a estimativa do coeficiente. Alguns pontos de alto impacto podem alterar significativamente o coeficiente, dependendo se estão presentes ou não. A Figura 10 mostra claramente que nos estágios iniciais (março, abril e maio de 2010), existem vários pontos de dúvida. Isso não é surpreendente, e o Plano B em seu artigo [2] mencionou que a coleta de dados para o período inicial estava repleta de certas dificuldades.
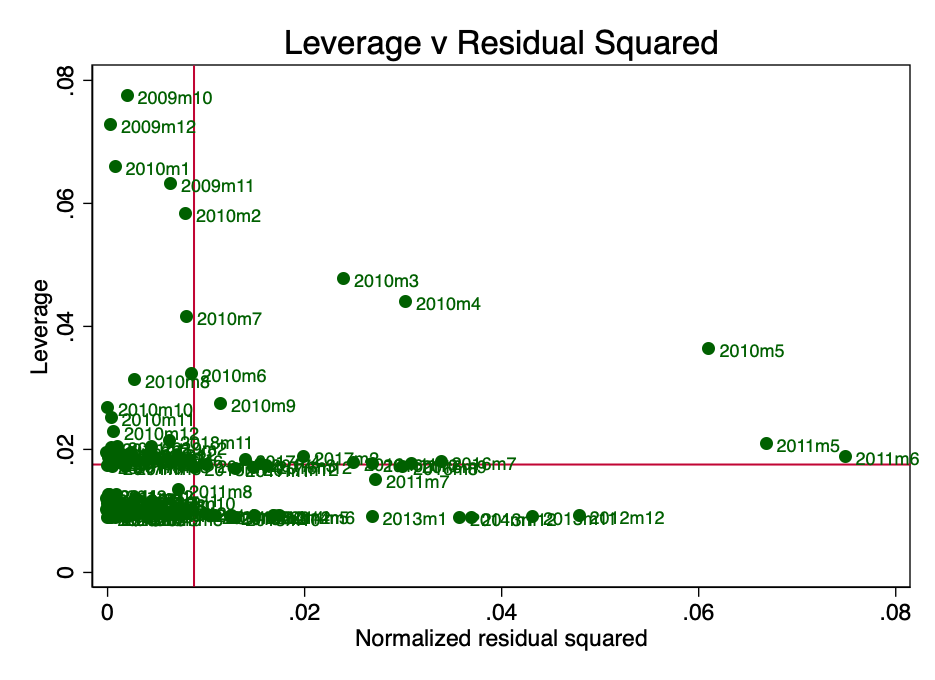
Figura: 10 - força de ação e resíduos normalizados ao quadrado.
Se executarmos novamente a regressão sem esses pontos (supondo que haja algum erro neles), então, como sabemos sobre o problema de heterocedasticidade, precisamos usar estimativas robustas.
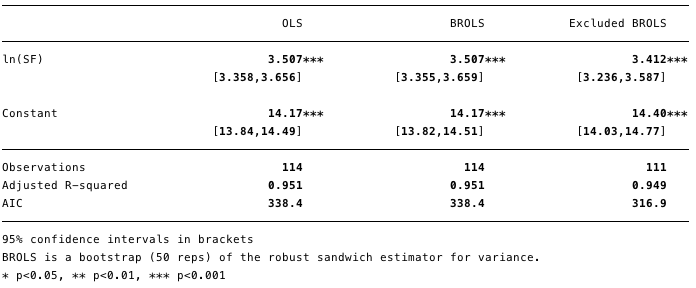
Figura: 11 - a remoção de pontos com alta força de impacto alterou significativamente o valor calculado de [β] e melhorou o valor do Akaike Information Criterion (AIC).
A Figura 11 mostra que a remoção dessas remoções desses três pontos altera significativamente o [β] e o valor do critério de informação de Akaike é significativamente reduzido, o que indica que o modelo é o melhor apesar do R² mais baixo.
Resumo do OLS
O diagnóstico básico indica vários problemas pequenos e solucionáveis com os mínimos quadrados originais. Neste estágio, não podemos refutar H0.
Stationarity
Um processo com ordem total igual a 0 é chamado estacionário.(por exemplo, eu(0)). Um processo não estacionário é I(1) ou mais. Calcular uma integral neste contexto é mais uma soma de diferenças com uma mudança de tempo. I(1) significa que subtrair o primeiro atraso de cada valor da série resulta em um processo I(0). É bem sabido que a regressão em séries temporais não estacionárias pode levar à identificação de relações espúrias.
As Figuras 12 e 13 abaixo mostram que não podemosrefute a hipótese nula do teste de Dickey-Fuller estendido (ADF). A hipótese nula do teste ADF é que os dados são não estacionários, ou seja, não se pode argumentar que os dados são estacionários.
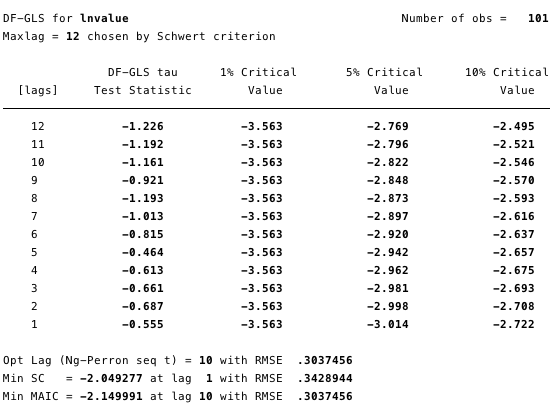
Figura: 12 - Teste Dickey-Fuller estendido para raiz unitária em ln (custo).
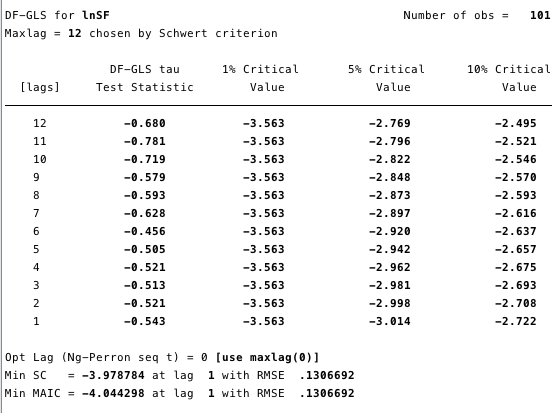
Figura: 13 - Teste Dickey-Fuller estendido para raiz unitária em ln (S2F).
O teste Kwiatkowski-Phillips-Schmidt-Shin (KPSS) é um teste complementar de estacionariedade aos testes ADF. A hipótese nula do KPSS é queos dados são estacionários.Como você pode ver nas Figuras 14 e 15, podemos refutar a estacionariedade para a maioria das defasagens em ambas as variáveis.


Figura: 14 e 15 - Teste KPSS contra a hipótese nula de estacionariedade.
Os testes KPSS provam que essas duas séries, forasem dúvida, não são estacionários. E há um problema com isso. Se a série não for estacionária pelo menos em relação à tendência, o método OLS pode identificar dependências falsas. A única coisa que podíamos fazer era pegar a diferença entre o logaritmo e o valor mensal de cada variável e reconstruir nossos mínimos quadrados. No entanto, devido ao fato dessa questão ser bastante difundida nos círculos econométricos, temos um framework muito mais robusto chamado cointegração.
Cointegração
A cointegração é uma maneira de lidar com um casal(ou mais) processa I (1) e determina se existe uma relação entre eles e em que consiste. Como uma ilustração clara de cointegração, um exemplo simplificado de um bêbado e seu cachorro é freqüentemente citado [3]. Imagine um homem bêbado voltando para casa enquanto passeava com o cachorro na coleira. O bêbado cambaleia ao longo de toda a largura da estrada de uma forma totalmente imprevisível. O cão também se move um tanto caoticamente: fareja as árvores, late, cava algo com as patas - um cachorrinho tão inquieto. No entanto, o raio de movimento do cão será limitado pelo comprimento da guia segurada pelo bêbado. Ou seja, pode-se argumentar que, em qualquer ponto do percurso do bêbado, o cão estará a um alcance de distância da coleira dele. (É claro que não podemos prever a direção do bêbado em um dado momento, mas estará dentro da coleira.) Esta é uma metáfora muito simplificada para a cointegração - o cão e seu dono se movem juntos.
Compare isso com a correlação:Digamos que um cão vadio segue um cão bêbado por 95% do seu caminho e, em seguida, foge com um latido na direção oposta após um carro que passa. A correlação entre as rotas de um cão de rua e de um bêbado seria muito forte (literalmente R²: 95%), no entanto, como muitas conexões acidentais de um bêbado, essa proporção não significaria absolutamente nada - não pode ser usada para prever o localização de um bêbado, já que para alguns um fragmento do caminho, a previsão baseada nesses dados se revelará correta, mas para algumas partes será completamente imprecisa.
Para encontrar a localização de um bêbado, primeiro precisamos entender qual especificação de ordem de atraso deve ser usada em nosso modelo.
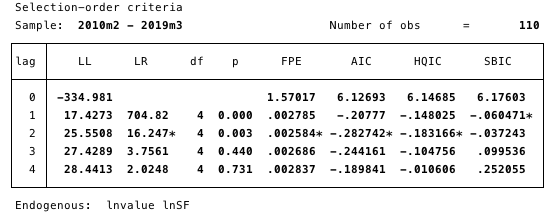
FIG. 16 é uma especificação de uma ordem de latência. O valor mínimo de AIC usado para a determinação.
Aqui, determinamos a ordem de latência mais adequada para a pesquisa, escolhendo o valor AIC mínimo de ordem 2.
Em seguida, precisamos determinar se há um relacionamento de cointegração. O framework Johansen [5, 6, 7] nos dá um excelente kit de ferramentas para isso.
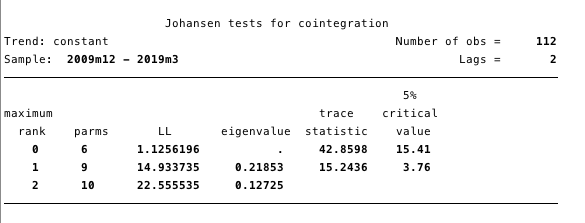
FIG. 17 - Teste de cointegração de Johansen.
Os resultados apresentados na Figura 17 nos dão motivos para acreditar que existe pelo menos uma equação de cointegração entre ln (custo) e ln (S2F).
Definimos nosso VECM como:
Δy@t =αβ`y@t-1+Σ(Γ@iΔy@t-1)+v+δt+ε@t
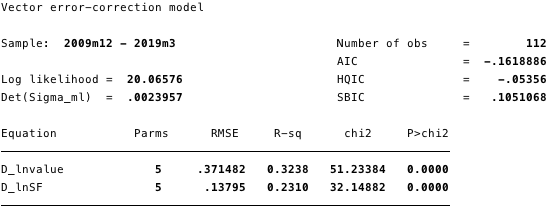
FIG. 18 - informações sobre todas as equações do modelo.
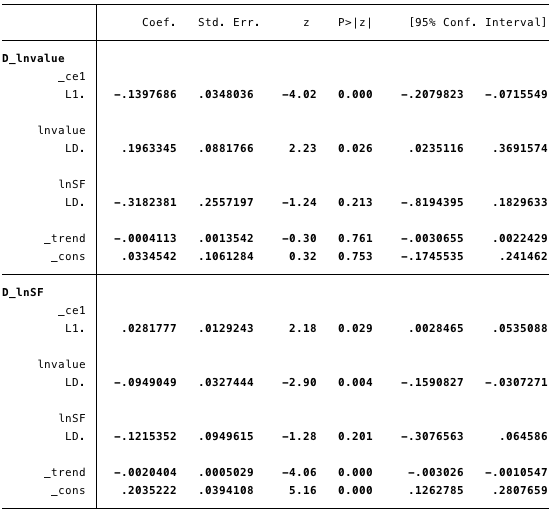
FIG. 19 - valores calculados de parâmetros de curto prazo e suas estatísticas.

FIG. 20 é uma equação de cointegração para o modelo.

FIG. 21 é o critério de informação Akaike para VECM.
Nas figuras acima, temos os seguintes valores calculados:
- [α] = [-0,14, 0,03]
- [β] = [1, -4,31],
- [v] = [0,03, 0,2] e
- [Γ] = [0,196, -0,095 -0,318, -0,122].
No geral, o resultado indica que o modeloserve bem. O coeficiente ln (S2F) na equação de cointegração é estatisticamente significativo, assim como os parâmetros de ajuste. Os parâmetros de ajuste indicam que se as previsões da equação de cointegração forem positivas, então ln (custo) está abaixo de seu valor de equilíbrio, uma vez que o coeficiente de ln (custo) na equação de cointegração é negativo. O valor calculado do coeficiente [D ln (custo)] L. ce1 é -0,14.
Assim, se o valor do bitcoin for muitoé pequeno, ele sobe rapidamente de volta ao nível de conformidade In (S2F). O fator calculado [D ln (S2F)] L. ce1 de 0,028 implica que se o valor do bitcoin for muito baixo, ele se ajustará ao nível de equilíbrio.
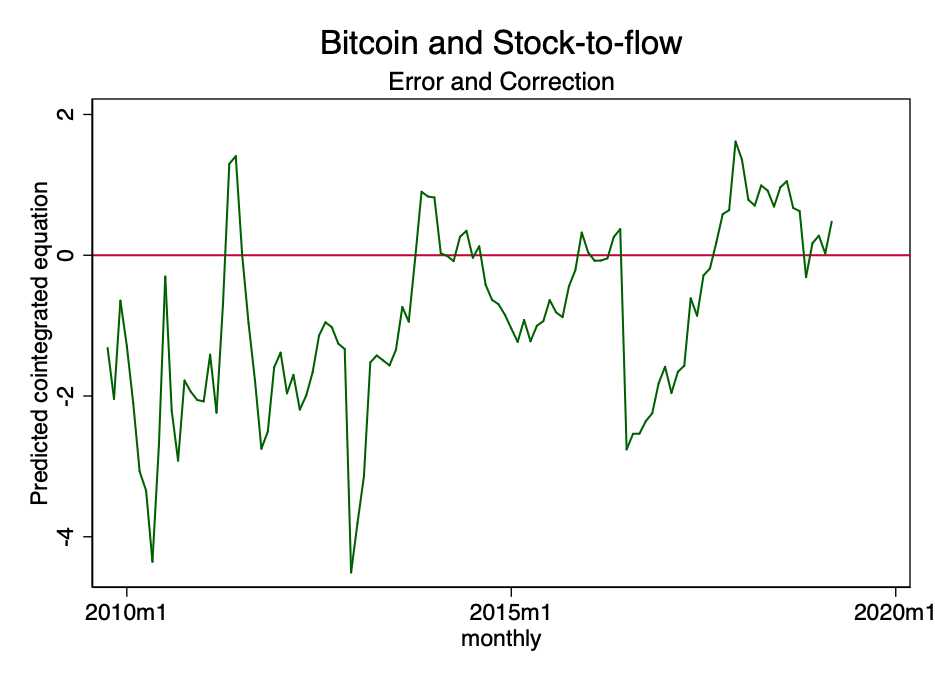
FIG. 22 - equação de cointegração prevista.
A figura acima mostra que o resultado da equação de cointegração tende a tender para zero. Embora formalmente possa ser não estacionário, definitivamente tende a ser estacionário.
Do manual do usuário do software Stata:
Matriz de acompanhamento para VECM com K endógenode variáveis (intrassistêmicas) e equações de cointegração r tem autovalores Kr. Se o processo for estável, então os módulos dos autovalores restantes r são estritamente menores que um. Como não há distribuição geral para os módulos dos autovalores, pode ser difícil determinar se eles estão muito próximos de um.
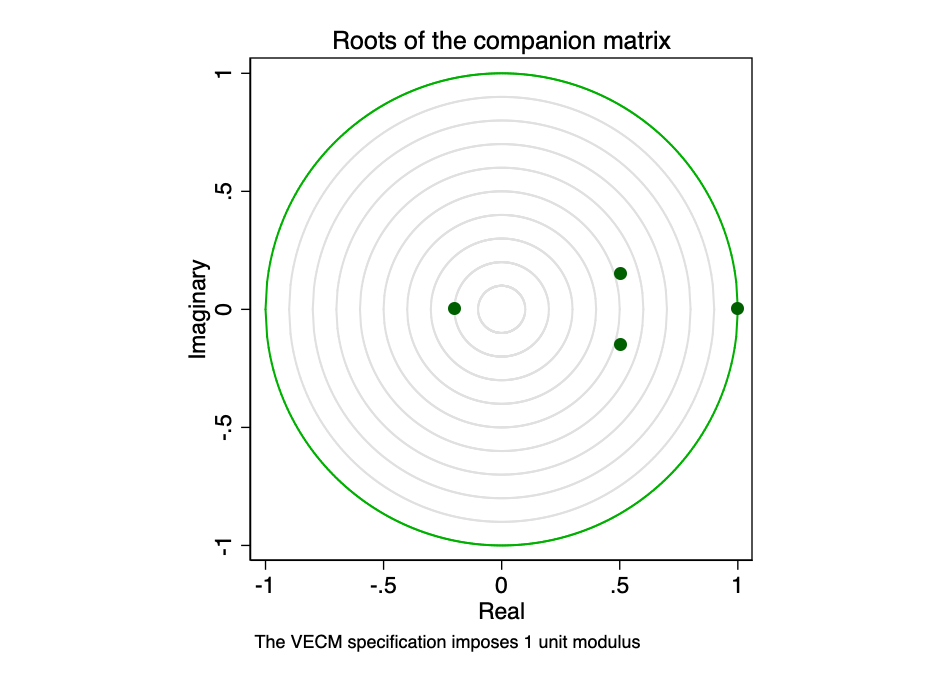
FIG. 23 - as raízes da matriz acompanhante.
Representação gráfica de valores própriosmostra que nenhum dos autovalores restantes está perto da borda do círculo unitário. Testar a robustez de nosso modelo não indica que ele está errado.
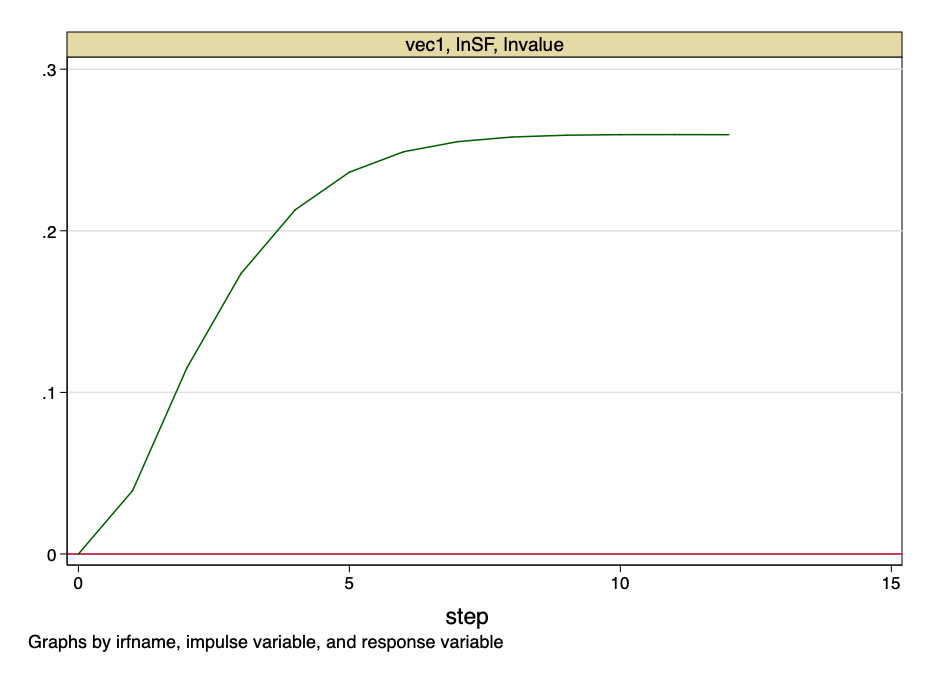
FIG. 24 - função de resposta ao impulso.
A figura acima indica que o salto ortogonalizado para o valor S2F tem um impacto permanente no valor do bitcoin.
E neste ponto traçamos a linha.A proporção de reservas para crescimento não é uma variável aleatória... Esta é uma função com um valor conhecido ao longo do tempo.Não haverá saltos nos valores S2F - seu custo pode ser calculado com precisão com antecedência. No entanto, este modelo fornece evidências muito fortes de que existe uma relação fundamental não falsa entre o valor S2F e o valor do bitcoin.
Limitações
Neste estudo não levamos em consideração nenhumfatores interferentes (confundidores). Dadas as evidências acima, é improvável que quaisquer fatores de confusão possam ter um impacto significativo na nossa conclusão – não podemos rejeitar H0. Nósnão podeafirmam que não há relação entre a relação estoque/crescimento e o valor do Bitcoin. Se fosse esse o caso, não haveria equação de cointegração.
Conclusão
Embora alguns dos modelos apresentados aqui comOs pontos de vista do critério de informação de Akaike são superiores ao modelo original do Plan B, todos eles falham em refutar a hipótese de que a relação estoque / ganho é um preditor importante e não falso do preço do bitcoin.
Para ilustrar, voltemos à metáfora do bêbado.do exemplo acima: se você comparar o valor do bitcoin com o de um bêbado, a proporção Estoque / Fluxo não é o cachorro que ele conduz na coleira, mas sim a estrada que ele anda. O bêbado cambaleia em toda a largura da estrada, às vezes escorregando, pulando curvas ou até mesmo cortando esquinas, mas geralmente aderindo à estrada para casa.
Ou seja, em resumo, o bitcoin é um bêbado e a relação estoque / ganho é o caminho que ele toma.
Materiais citados
- Karl Popper, «A Lógica da Pesquisa Científica» (1959)
- https://bitnovosti.com/2019/04/03/modelirovanie-tseny-bitkojna-ishodya-iz-ego-defitsitnosti/
- Murray, M. (1994). Um bêbado e seu cachorro: uma ilustração de cointegração e correção de erros.The American Statistician, 48(1), 37-39. doi: 10.2307 / 2685084
- https://github.com/100trillionUSD/bitcoin
- Johansen, S. 1988. Análise estatística de vetores de cointegração. Journal of Economic Dynamics and Control 12: 231-254.
- Johansen, S. 1991. Estimativa e teste de hipótese de vetores de cointegração em modelos de vetores autoregressivos gaussianos. Econometrica 59: 1551-1580.
- Johansen, S. 1995. Likelihood-Based Inference in Cointegrated Vector Autoregressive Models. Oxford: Oxford University Press.
- Becketti, S. 2013. Introduction to Time Series Using Stata. College Station, TX: Stata Press.
Notas:
- Para todas as análises, foi utilizado o software Stata 14.
- O artigo não contém recomendações financeiras.
</p>
Leia isto:
 Crescimento de hash do Bitcoin garantido pelo lançamento de 500.000 novos mineradores ASIC
Crescimento de hash do Bitcoin garantido pelo lançamento de 500.000 novos mineradores ASIC
 Duas semanas antes da queda do Bitcoin para US $ 8.000
Duas semanas antes da queda do Bitcoin para US $ 8.000
 Mineração de criptomoeda no ASIC: relevância, rentabilidade, modelos
Mineração de criptomoeda no ASIC: relevância, rentabilidade, modelos
 Modelando o preço do bitcoin com base em sua escassez
Modelando o preço do bitcoin com base em sua escassez
 Inicialização PRISM. Análise do desenvolvimento do modelo no exemplo No. 1
Contrato Social Bitcoin
Inicialização PRISM. Análise do desenvolvimento do modelo no exemplo No. 1
Contrato Social Bitcoin